
The use cases for extracting content from a website are diverse. Extracting content from a website is primarily used for data analysis, search engine indexing, competition analysis, lead generation or content aggregation.
Websites themselves are realized with HTML. HTML is a tree-based language that uses tags to structure content. This means that it represents a nested structure of markup elements (HTML tags) and texts. Many of the tags do not contain the actual textual content of the website but are used for styling, scripts or image display. Furthermore, the menu, the sidebar or the footer menu can often be neglected when it comes to reading the actual central textual content of a website.
This is the reason why the content scraping of a website can sometimes be time-consuming. At the beginning of the text analysis you often have to deal with the HTML code of the respective page. I myself then try to determine the selectors that represent the HTML elements in which the desired text or content is contained.
Table of Contents
- Visualize HTML Code as Network
- Statistical Approach
- Prerequisites
- Base Implementation
- Necessary Imports
- Get HTML node text content length
- HTML Code Traversal Function
- Initial Execution
- First Result Ouput
- First Optimiziation – Removal of unnecessary or empty tags
- Second Result Ouput
- Second Optimiziation – Metric
- Third Result Ouput
- Last optimisation – Extraction of the main content selector
- Last Result Output
- Conclusion
Visualize HTML Code as Network
The following graphic visualizes the HTML of this website with its tree structure as a network. It is easy to see how complicated the structure of a website in HTML code is. And this is still a simple website.

Statistical Approach
The idea of the statistical approach is to determine all selectors of a web page with textual content. Selectors pointing to empty elements or elements without semantic content are filtered out later. In the end, the selector that points to the elements that contain the main content should be determined.
Prerequisites
As this is an advanced Python application, the following blog articles are helpful:
Base Implementation
The following code snippets uses Beautiful Soup to traverse the HTML code of a web page. It extracts the selector path to the elements and identifies the length of the text content and the number of sub-elements of each element found. First you have to install beautiful soup.
pip install beautifulsoup4
Necessary Imports
The requests library is imported to send HTTP requests. The BeautifulSoup and Tag classes from the bs4 library are imported. BeautifulSoup is a Python library used for web scraping purposes to pull the data out of HTML and XML files. Tag is a class in BeautifulSoup that represents an HTML or XML tag. An empty dictionary data is initialized to store the information about each element.
# Importing the `requests` library to make HTTP requests
import requests
# Importing `BeautifulSoup` and its `Tag` class from the `bs4` library
from bs4 import BeautifulSoup, Tag
# Initialize an empty dictionary to store HTML tag selectors and their corresponding lengths
data = {}
Get HTML node text content length
The function get_text_length(node) is defined to calculate the length of the text content of a node. If the node is a Tag, it recursively calculates the length of the text content of its children. If the node is not a Tag, it returns the length of the stripped text content.
# Define a function that calculates the length of the text content within a given node (HTML element or string)
def get_text_length(node):
# If `node` is an instance of the `Tag` class (i.e., it represents an HTML element)
if isinstance(node, Tag):
# Recursively calculate the total length of all children nodes' text contents
return sum(get_text_length(child) for child in node.children)
else:
# Otherwise, strip leading/trailing whitespaces from `node` (if it's a string), then measure its length
return len(node.strip())
HTML Code Traversal Function
The function traverse_tree(node, parent_selector=None) is defined to traverse the tree structure of the HTML code. It takes a node and its parent selector as arguments. If the node is a Tag, it constructs the selector path by concatenating the parent selector and the node’s name. If there’s no parent selector, it simply uses the node’s name. It calculates the text length of the node using the get_text_length function. If the selector is already in the data dictionary, it adds the text length to the existing length and increments the child count. If the selector is not in the dictionary, it initializes a new entry with the text length and sets the child count to 1.
It then recursively calls traverse_tree on each child of the node, passing the selector as the parent selector.
# Define a recursive function that traverses the HTML tree, collecting information about tags and their lengths
def traverse_tree(node, parent_selector=None):
# If `node` is an instance of the `Tag` class
if isinstance(node, Tag):
# Construct a CSS selector based on `parent_selector` and this node's name
selector = parent_selector + ' > ' + node.name if parent_selector else node.name
# Get the text length within `node` using the `get_text_length()` helper function defined earlier
text_length = get_text_length(node)
if selector in data: # If we have already encountered this selector before
# Increment the cumulative length by adding `text_length`
data[selector]["length"] += text_length
# Increase the number of child elements under this selector by one
data[selector]["childs"] += 1
else:
# Otherwise, initialize a new entry with zero values for both length and child count
data[selector] = {"length": 0, "childs": 0}
# Set the initial value of the length field
data[selector]["length"] = text_length
# Set the initial value of the child count field
data[selector]["childs"] = 1
for child in node.children: # Iterate through every direct child node
# Call `traverse_tree()` recursively, passing along the current selector as the parent
traverse_tree(child, selector)
Initial Execution
Now we can call the previously created functions for a specific url. First, we send an HTTP GET request to the specified URL. The response from the server is stored in the variable response.
Then we convert the HTML code of the web page into a Beautiful Soup object. We then call the traverse_tree method, which saves the desired data in the previously created data variable.
After the HTML code has been traversed, we use a loop that outputs all recognised selectors, the number of subordinate elements and the text length of the selector.
Please note that the following code does not respect the robots.txt or nofollow directives. This means that you must manually check whether the website operator allows the url used to be crawled.
# Make an HTTP request to fetch webpage content
response = requests.get("https://developers-blog.org")
# Parse the fetched HTML page into a Beautiful Soup object
soup = BeautifulSoup(response.text, 'html5lib')
# Start parsing the HTML document by calling `traverse_tree()` on the root <html> tag
traverse_tree(soup.html)
# Initialize counter variable to keep track of how many unique selectors were identified
count = 0
# Print out the results
for selector, selector_data in data.items():
print(f"{selector} ({selector_data['childs']}): {selector_data['length']}")
count += 1
# Output the final count of distinct selectors found
print("Identified Selectors:", count)
First Result Ouput
Our first version of our code still determines a very large number of selectors. The total number of selectors determined is 91. It also outputs selectors for tags that do not represent text or negligible elements such as the navigation nav, aside or footer.
html (1): 22564
html > head (1): 15788
...
html > head > style (3): 10397
html > body (1): 6776
html > body > div (1): 5999
html > body > div > header (1): 272
...
html > body > div > header > div > nav > div > div > a > i (1): 0
...
html > body > div > header > div > nav > div > div > button > span (1): 4
html > body > div > div (1): 5523
html > body > div > div > div (1): 5515
...
html > body > div > div > div > main > div > div > div > div > div > div > p (40): 4406
...
html > body > div > footer (1): 168
...
html > body > script (9): 772
Identified Selectors: 91
First Optimiziation – Removal of unnecessary or empty tags
We now need to extend the code so that certain parts of the tree are skipped or removed.
Removal of selectors without text:
In the new version, we check whether the text length of the current node is 0. If this is the case, the selector will not be added to the result stored in data or removed if it already exists.
Removal of unnecessary parent selectors:
If parent selectors have the same text content length as the current child, they will be removed.
Exclusion of unnecessary tags
We also exclude that certain elements such as nav, footer, aside etc., which are mostly used for navigation on the website.
# List of tags to exclude from the traversal process
traversing_tag_excludes = ['sript', 'footer', 'nav', 'aside', 'style']
def traverse_tree(node, parent_selector=None):
# Check if node is an instance of Tag and its name is not in the exclusion list
if isinstance(node, Tag) and node.name not in traversing_tag_excludes:
# Construct a selector string by combining parent's selector with current tag's name
selector = parent_selector + ' > ' + node.name if parent_selector else node.name
text_length = get_text_length(node) # Get the length of the text in the node
# If a parent selector exists and it's present in data,
# check if its text length is equal to current node's text length
if parent_selector is not None and parent_selector in data:
if data[parent_selector]['length'] == text_length:
data.pop(parent_selector) # If so, remove it from the data
# Check if the node's text length is non-zero
if text_length != 0:
if selector in data:
data[selector]["length"] += text_length
data[selector]["childs"] += 1
else:
data[selector] = {"length": 0, "childs": 0}
data[selector]["length"] = text_length
data[selector]["childs"] = 1
# Recursively traverse through the children of current node
for child in node.children:
traverse_tree(child, selector)
Second Result Ouput
Thanks to our optimization measures, we were able to reduce the number of identified selectors to 25. Wow. That’s an improvement of around 85%. Nevertheless, the question arises as to which selector or selectors represent the main content. 25 results are still too many.
html (1): 5378
html > head (1): 230
html > head > title (1): 61
html > body (1): 5148
html > body > div (1): 5143
html > body > div > header (1): 80
html > body > div > header > div (1): 37
html > body > div > div (1): 5027
html > body > div > div > div (1): 5019
html > body > div > div > div > main (1): 4988
html > body > div > div > div > main > div (2): 4959
html > body > div > div > div > main > div > h1 (1): 15
html > body > div > div > div > main > div > p (1): 19
html > body > div > div > div > main > div > div (2): 4922
html > body > div > div > div > main > div > div > div > div > div > div (10): 4901
html > body > div > div > div > main > div > div > div > div > div > div > p > a (30): 3846
html > body > div > div > div > main > div > div > div > div > div > div > a > h2 (10): 495
html > body > div > div > div > main > div > div > div > div > div > div > p (39): 4400
html > body > div > div > div > main > div > div > div > div > div > div > p > span > span (20): 380
html > body > div > div > div > main > div > div > div > div > div > div > p > span > span > time (20): 320
html > body > div > div > div > main > div > div > div > div > div > div > p > span > span > span (10): 10
html > body > div > div > div > main > div > div > div > div > div > div > p > span (39): 527
html > body > div > div > div > main > div > div > div > div > div > div > p > span > span > a (10): 50
html > body > div > div > div > main > div > div > div > div > div > div > p > span > a (10): 150
html > body > div > a > span (1): 6
Identified Selectors: 25
Second Optimiziation – Metric
To further narrow down the results based on selectors, we need to establish a metric that best represents the main text. We have the following data available: the selector, the text length, and the number of child elements.
The multiplication of text length and number of children best represents the content. When sorting the results based on this calculation, we should prioritize the selectors that represent the main content.
# The following method sorts the data dictionary by the product
# of the "length" and "childs" values in each item, in descending order:
sorted_data = sorted(data.items(), key=lambda x: x[1]["length"] * x[1]["childs"], reverse=True)
for selector, selector_data in sorted_data:
print(f"{selector} ({selector_data['childs']}): {selector_data['length']}")
count += 1
print(count)
Third Result Ouput
We still have 25 results, but those that represent the most important content according to our metric are now displayed sorted by importance.
html > body > div > div > div > main > div > div > div > div > div > div > p (39): 4400
html > body > div > div > div > main > div > div > div > div > div > div > p > a (30): 3846
html > body > div > div > div > main > div > div > div > div > div > div (10): 4901
html > body > div > div > div > main > div > div > div > div > div > div > p > span (39): 527
html > body > div > div > div > main > div (2): 4959
html > body > div > div > div > main > div > div (2): 4922
...
25
If we now run the first selector in the web console we find that this is indeed the most important content.
var elements = [...document.querySelectorAll("html > body > div > div > div > main > div > div > div > div > div > div > p")];
elements.forEach((e) => e.style.border = '3px dashed lightcoral');
The result then looks like this:
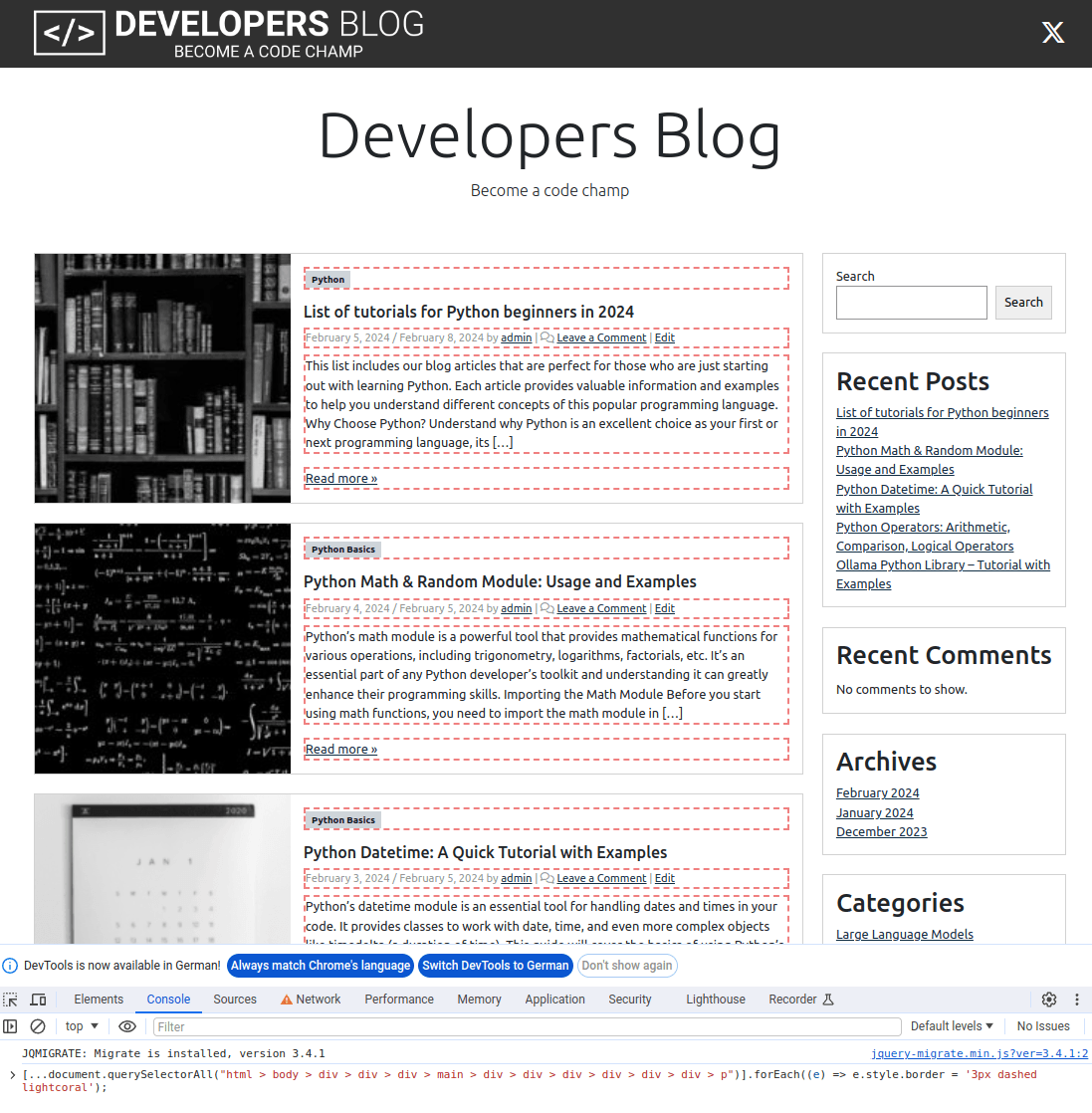
Last optimisation – Extraction of the main content selector
We now know which selectors point to the elements of the HTML code that contain the most important textual content of the website according to our metric.
However, if we look closely at the last screenshot of the page with the identified elements, we realise that the title was not identified by the first selector.
Therefore, we now only want to identify a selector that leads us directly to the main content.
We can achieve this by overlaying the first three selectors. We then assume that the part of the selector that is the same for all three displays the main text content of the web page.
To do this, we create a new function called get_intersection_path. This function takes a list of data entries, each containing a path string. It finds the common path between the first three entries and outputs it.
def get_intersection_path(data):
# Initialize an empty list to store the common path
common_path = []
# Split the first element of each entry in the data list into a list of paths
# Only consider the first three entries in the data list
paths = [entry[0].split(" > ") for entry in data[:3]]
# Find the common path by iterating over the paths
# The loop will stop at the first uncommon path or when the end of the shortest path is reached
for i in range(min(len(paths[0]), len(paths[1]), len(paths[2]))):
# If the paths are the same at the current index for all three paths, add it to the common path
if paths[0][i] == paths[1][i] == paths[2][i]:
common_path.append(paths[0][i])
# If the paths are not the same, stop the loop
else:
break
# Join the common path elements with " > " to form a string
result = " > ".join(common_path)
# Print the main content selector
print("Main Content Selector:", result)
sorted_data = sorted(data.items(), key=lambda x: x[1]["length"] * x[1]["childs"], reverse=True)
get_intersection_path(sorted_data)
Last Result Output
The result of the function is impressive. It provides us with a selector that gives us all the essential text content of the web page.
Main Content Selector: html > body > div > div > div > main > div > div > div > div > div > div > div
If we now look at the web page again, we can see that all the main text content is found with the determined selector.
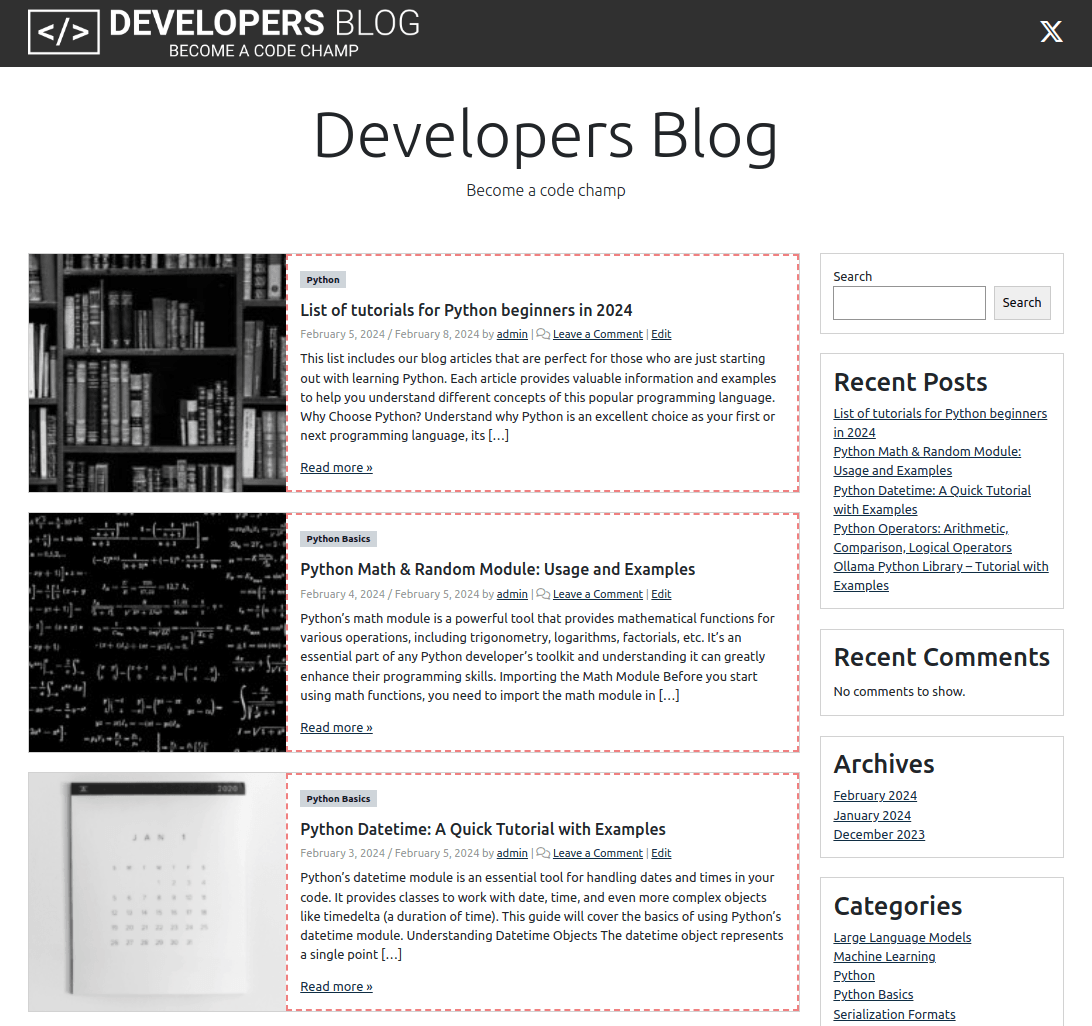
Conclusion
If you have a similar challenge to me, then perhaps the path shown here can help you to identify important content. I have now tried several websites with this procedure. The correct selector was found for most of them. However, this is only a prototype implementation, which certainly still has room for improvement.