
Introduction
Website scraping or crawling is an automated method used to extract large amounts of data from websites. It’s a useful tool when you want to gather information from the internet programmatically, which can be used for various purposes such as market research, price monitoring, and more. In this blog post, we will discuss how to implement a website scraper with Python.
Table of Contents
- Introduction
- Website Scraper Approach
- The Goals
- WebsiteResult Class
- WebsiteScraper Class
- Example: Extract Headings – extract_headings
- Example: Extract Images – extract_images
- Example: Extract Internal Links – extract_internal_links
- Example: Transform Result to Graph – transform_graph
- Conclusion
Website Scraper Approach
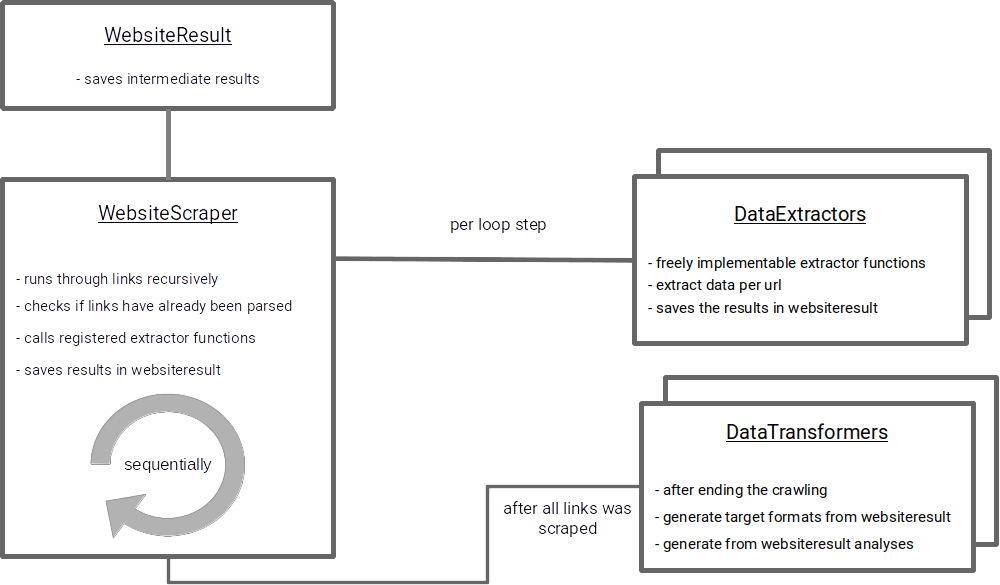
To program a crawler in python we will program two main classes, WebsiteResult and WebsiteScraper, which are used for web scraping tasks.
WebsiteResult stores the results of scraping a specific URL, initializes and evaluates data structures for extracted information.
WebsiteScraper performs the actual web scraping operations, taking a URL as a starting point and providing methods for retrieving robots.txt, handling link relationships and registering extraction/transformation functions.
The Goals
The goal of this implementation of a website crawler in Python is the extraction of internal links, headlines and images. Finally, the relations of all subpages should be displayed as a network graph. the whole thing should work modularly. This means that it should be possible to create new extraction functions and output formats without having to adapt the core logic.
WebsiteResult Class
The WebsiteResult class is used to store the results of a web scraping operation for a specific URL. It takes a URL as input during initialization and parses it into its components (protocol, domain).
The class also provides methods to evaluate and initialize data structures for storing extracted information about the website, such as titles of pages or metadata from HTML tags.
from urllib.parse import urlparse
class WebsiteResult:
def __init__(self, url):
# Parsing the given URL to extract its components
parsed = urlparse(url)
# Storing the protocol (http, https, etc.) of the URL
self.protocol = parsed.scheme
# Storing the domain (e.g., example.com) of the URL
self.domain = parsed.netloc
# Initializing a dictionary to
# store data related to the website
self.data = {
"global": {},
"paths": {}
# Placeholder for data to paths
}
# Method to evaluate and initialize
# data storage for a specific path
def evaluate_path_data(self, path, key=None):
# If the path is not already present
# in the data dictionary, add it
if path not in self.data['paths']:
self.data['paths'][path] = {}
# If a key is provided and it's not already present
# in the path's data dictionary, add it
if key is not None:
if key not in self.data['paths'][path]:
self.data['paths'][path][key] = []
# Method to extract the path component from a given URL
def get_path(self, url):
parsed = urlparse(url)
path = parsed.path.strip()
if len(path) == 0:
path = '/' # If the path is empty, set it to '/'
return path
# Method to set data for a specific URL and key
def set_data(self, url, key, data):
# Extracting the path from the URL
path = self.get_path(url)
# Ensuring that the path data is initialized
self.evaluate_path_data(path)
# Setting the provided data for the given key
self.data['paths'][path][key] = data
# Method to append data for a specific URL and key
def append_data(self, url, key, data):
# Extracting the path from the URL
path = self.get_path(url)
# Ensuring that the path data is initialized
self.evaluate_path_data(path, key)
# Appending the provided data to the list
self.data['paths'][path][key].append(data)
# Method to check if a specific URL has been scraped
def is_scraped(self, url):
# Extracting the path from the URL
path = self.get_path(url)
# Checking if the path exists in the
# data dictionary and if 'is_scraped' key is True
if path in self.data['paths']:
if self.data['paths'][path]['is_scraped'] == True:
return True
return False
WebsiteScraper Class
The WebsiteScraper class is used to perform web scraping operations on a specific URL. It takes a URL as input during initialization and uses it as the starting point for its crawling operations. The class provides methods for fetching the site’s robots.txt file, checking whether a given URL should be fetched based on the site’s rules, handling link rel attributes such as nofollow, registering functions to extract information from web pages (extractors), and transforming the results of scraping operations (transformers).
The crawl method is used to recursively fetch web pages starting from a given URL. It fetches the page’s HTML content using the requests library, parses it into a BeautifulSoup object for easier manipulation, and then extracts information about the page using registered extractor functions (if any). The function also looks for links in the page and recursively crawls internal pages that are not yet scraped.
The process method is used to start the web scraping process by calling the crawl method, then applies any registered transformer functions to the results of the scraping operation before returning them.
This code uses several external libraries such as requests for making HTTP requests, BeautifulSoup for parsing HTML content, and urllib.robotparser for fetching and parsing robots.txt files. It also uses regular expressions (re) to handle certain aspects of the web scraping process.
Please note that this code is a basic example and may not cover all edge cases or specific requirements in a real-world scenario, such as handling different types of links, dealing with relative URLs, following redirects, error handling, concurrency for faster crawling, etc.
from bs4 import BeautifulSoup
import requests
from urllib.robotparser import RobotFileParser
from urllib.parse import urlparse
class WebsiteScraper:
def __init__(self, url):
self.url = url
self.extractors = []
self.transformers = []
protocol, domain, start_path = self.parse_url(url)
self.protocol = protocol
self.domain = domain
self.start_path = start_path
self.counter = 0
# Parse the provided url string into its
# component parts protocol, domain, path
def parse_url(self, url):
if not url or "#" in url:
return None, None, None
parsed = urlparse(url)
protocol = parsed.scheme
domain = parsed.netloc
path = parsed.path
if protocol is None:
protocol = self.protocol
if domain is None:
domain = self.domain
return protocol, domain, path
# Prepare an absolute URL from the
# relative href attributes
def prepare_url(self, href):
protocol, domain, path = self.parse_url(href)
if protocol == None or domain == None:
return None
else:
return f"{protocol}://{domain}{path}"
# Determine whether the provided url is internal
def is_internal_url(self, url):
protocol, domain, path = self.parse_url(url)
if domain == self.domain:
return True
else:
return False
def get_webpage_result_skeleton(self, url):
protocol, domain, path = self.parse_url(url)
return WebsiteResult(protocol, domain)
# Fetch and parse the robots.txt
def fetch_robots_txt(self):
url = f'{self.protocol}://{self.domain}/robots.txt'
rp = RobotFileParser()
rp.set_url(url)
rp.read()
return rp
# Check whether the site allows access
# to the provided url
def should_fetch_url(self, url):
user_agent = requests.utils.default_user_agent()
robot_rules = self.fetch_robots_txt().can_fetch("*", url)
return robot_rules or (not self.domain) or (user_agent in robot_rules)
# Checks whether one of the rel values
# prohibits following the link
def handle_link_rel(self, link):
for rel in ['nofollow', 'noindex']:
if rel in link.get('rel', ''):
return False
return True
# Flexible registration of data extractors
def register_extractor(self, func):
self.extractors.append(func)
# Flexible registration of result transformers
def register_transformer(self, func):
self.transformers.append(func)
def crawl(self, url = None, website_result = None):
# If no URL is provided, use the class's default URL.
if url is None:
url = self.url
# Initialize a WebsiteResult object if none was provided.
if website_result is None:
website_result = WebsiteResult(url)
# Mark this URL as scraped in the result data.
website_result.set_data(url, "is_scraped", True)
# Check if this URL is allowed by the site's
# robots.txt rules. If not, skip it.
if not self.should_fetch_url(url):
print(f"Skipping {url}: Disallowed by robots.txt")
return
# Send a GET request to the URL
# and parse the response text as HTML.
response = requests.get(self.url if url is None else url)
soup = BeautifulSoup(response.text, 'html.parser')
# If a meta tag with content "noindex"
# exists on the page, skip it.
meta_tag = soup.find('meta', attrs={
'name': 'robots',
'content': re.compile(r'noindex', re.IGNORECASE)
})
if meta_tag:
print(f"Skipping {url}: Noindex found")
return
# Try to find the title tag in
# the HTML and get its text content.
# If it doesn't exist, skip this URL.
title = soup.find('title')
if title is None:
return
# Print the counter and the page title.
print(self.counter, title.text)
self.counter +=1
# Store the page title in the result data.
website_result.set_data(url, "title", title.text)
# Run all extractors on this URL's HTML content and
# store their results in the result data.
for extractor in self.extractors:
extractor(soup, url, website_result)
# For every link found in the page's HTML,
# if it is an internal URL and
# follows site's rules, crawl it recursively.
for link in soup.find_all('a'):
href = link.get('href')
url = self.prepare_url(href)
if url is not None and self.is_internal_url(url):
if self.handle_link_rel(link):
protocol, domain, path = self.parse_url(href)
# If this URL has not been scraped yet,
# crawl it recursively.
if not website_result.is_scraped(path):
self.crawl(url, website_result)
# Return the result data for this URL after
# all its links have been processed.
return website_result
def process(self):
website_result = self.crawl()
for transformer in self.transformers:
transformer(website_result)
return website_result
Example: Extract Headings – extract_headings
This function extracts all heading tags (h1 to h6) from a given HTML content and stores them in the result data under a key named "headings". It takes as input the parsed HTML content (soup), the URL of the page they’re being run on (url), and an instance of WebsiteResult (website_result).
def extract_headings(soup, url, website_result):
# Find all heading tags (h1 to h6) in the HTML content.
headings = soup.find_all(['h1', 'h2', 'h3', 'h4', 'h5', 'h6'])
# For each heading, get its text and store it in the result data under a key named "headings".
for heading in headings:
website_result.append_data(url, "headings", heading.text.strip())
scraper = WebsiteScraper('https://developers-blog.org')
scraper.register_extractor(extract_headings)
results = scraper.process()
print(json.dumps(results.data['paths'], indent=4))
Output (cutout):
{
...
"/lambda-functions-in-python-with-examples": {
"is_scraped": true,
"title": "Lambda Functions in Python with Examples",
"headings": [
"Lambda Functions in Python with Examples",
"Table of Contents",
"What are Lambda Functions?",
"Lambda Function Syntax",
"Examples of Lambda Functions in Python",
"Example 1: Creating an Addition Function",
"Example 2: Using Lambda Functions as Arguments for Higher-Order Functions",
"Example 3: Filtering Elements Using Lambda Functions",
"Example 4: Using Lambda Functions as Callbacks",
"Conclusion",
"..."
]
}
...
}
Example: Extract Images – extract_images
This function extracts all image tags from a given HTML content and stores their source URLs and alt texts in a dictionary under a key named "images". It takes as input the parsed HTML content (soup), the URL of the page they’re being run on (url), and an instance of WebsiteResult (website_result)
def extract_images(soup, url, website_result):
images = soup.find_all('img')
for image in images:
alt_text = image.get('alt', '')
website_result.append_data(url, "images", {"src": image.get('src'), "alt": alt_text})
scraper = WebsiteScraper('https://developers-blog.org')
scraper.register_extractor(extract_images)
results = scraper.process()
print(json.dumps(results.data['paths'], indent=4))
Output (cutout):
{
...
"/lambda-functions-in-python-with-examples": {
"is_scraped": true,
"title": "Lambda Functions in Python with Examples",
"images": [
{
"src": ".../img/logo/developers-blog-logo.png",
"alt": "logo"
},
{
"src": ".../img/logo/developers-blog-logo.png",
"alt": "logo"
},
{
"src": ".../lambda-functions-in-python-with-examples-1.jpg",
"alt": ""
},
...
]
}
...
}
Example: Extract Internal Links – extract_internal_links
This function is designed to extract all the internal links from a webpage’s HTML content. It does this by searching for anchor (‘a’) tags in the HTML and checking if their href attribute points to an internal URL (i.e., a URL that belongs to the same website).
The function also includes some exclusions: it doesn’t include links containing certain words or regular expressions, such as ‘privacy-policy’, ‘imprint’, ‘/page’, ‘/category’, ‘admin’, and ‘uploads’.
It also checks if the href attribute of an anchor tag matches a specific pattern (e.g., ‘/2022/12/’) which might indicate a date-based URL structure.
The function then stores these internal links in the WebsiteResult object, under the key internal_links. The stored data is a list of unique paths to avoid duplicates and make it easier for other parts of the program to process the links.
def extract_internal_links(soup, url, website_result):
excluded_words = ['privacy-policy', 'imprint', '/page', '/category', 'admin', 'uploads']
internal_links = []
for link in soup.find_all('a'):
href = link.get('href')
internal_url = scraper.prepare_url(href)
if (internal_url is not None and
scraper.is_internal_url(internal_url) and not any(word in internal_url for word in excluded_words) and not re.match(r'^/\d{4}/\d{2}/$', href)):
internal_path = website_result.get_path(internal_url)
if internal_path not in internal_links:
internal_links.append(internal_path)
website_result.set_data(url, "internal_links", internal_links)
scraper = WebsiteScraper('https://developers-blog.org')
scraper.register_extractor(extract_internal_links)
results = scraper.process()
print(json.dumps(results.data['paths'], indent=4))
Output (cutout):
{
...
"/lambda-functions-in-python-with-examples": {
"is_scraped": true,
"title": "Lambda Functions in Python with Examples",
"internal_links": [
"/",
"/ollama-tutorial-running-large-language-models-locally/",
"/exception-handling-with-try-catch-in-python-with-examples/",
"/beautiful-soup-types-of-selectors-with-examples/",
"/python-website-scraping-automatic-selector-identification/",
"/beautiful-soup-a-python-library-for-web-scraping/",
...
]
}
...
}
Example: Transform Result to Graph – transform_graph
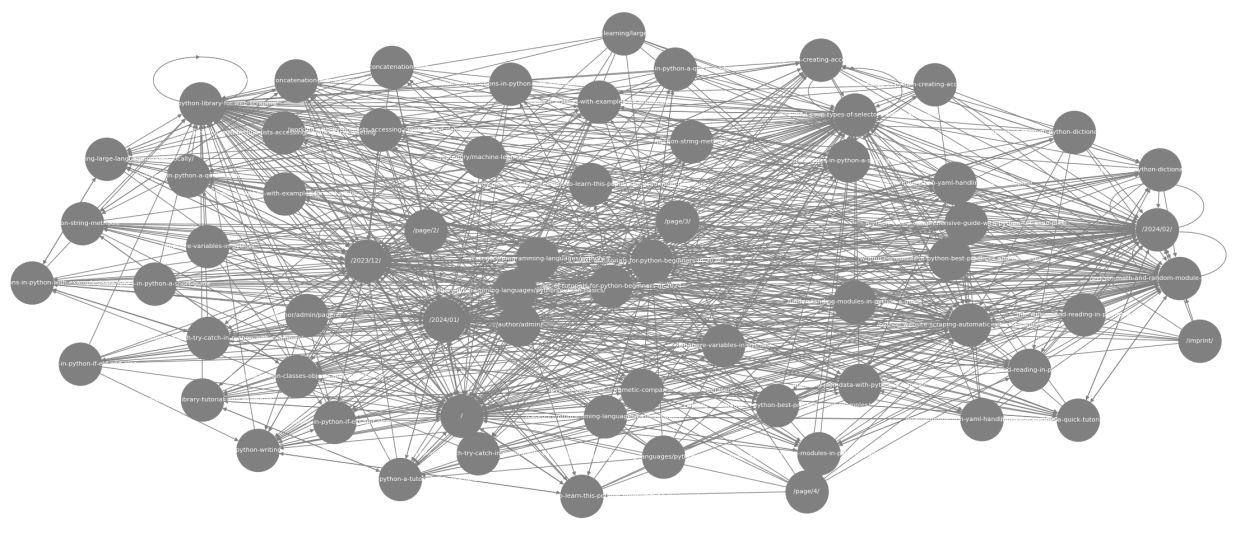
The transform_graph function is our first specific transformation function. It is used to transform the internal links extracted from a website (from the previous extraction method extract_internal_links) into a directed graph structure using the NetworkX library in Python.
This function takes as input an instance of WebsiteResult (website_result), which contains all the data extracted from the website, including the internal links for each page. The function then creates a new directed graph object and adds nodes to it based on these internal links. Each node represents a web page, and there is an edge between two nodes if one can be reached from the other (i.e. by following the link).
The resulting graph shows all pages that are connected to each other in the website structure.
def transform_graph(website_result):
# Create an empty directed graph object
graph = nx.DiGraph()
# Add the nodes and edges based on the internal links
for source_url, path_data in website_result.data["paths"].items():
for target_url in path_data.get("internal_links", []):
graph.add_edge(source_url, target_url)
# display the graph
plt.figure(figsize=(10, 10))
pos = nx.spring_layout(graph, seed=42)
nx.draw(graph, pos, with_labels=True, node_size=3000, node_color='gray', font_size=8, font_color='white', edge_color='gray', arrows=True)
plt.show()
scraper = WebsiteScraper('https://developers-blog.org')
scraper.register_extractor(extract_internal_links)
scraper.register_transformer(transform_graph)
results = scraper.process()
Conclusion
To summarize, the Python website scraper presented here provides a solid foundation for extracting web data with Python.
Users can customize their scraping operations to meet specific requirements by defining custom extraction and transformation functions.
However, it is important to emphasize that this is only a prototype alpha implementation. Further work is needed to improve the overall robustness.
Also make sure that the links that are crawled by the crawler are allowed to be crawled (taking into account robots.txt, rel attributes, etc.).